
The Kubernetes Operator Pattern: teaching your cluster to manage anything
Contents
When you run kubectl apply, nothing executes your manifest directly. The API server writes your desired state to etcd, and a control loop running somewhere in the cluster notices the gap between what you asked for and what currently exists - then closes it. That loop is a controller. A Deployment is a controller. A ReplicaSet is a controller. The entire Kubernetes architecture is built on this pattern.
An operator is what happens when you take that same pattern and point it at something you own: a database, a DNS record, an SSL certificate, a Slack channel. The operator extends Kubernetes’ reconciliation model to resources that have nothing to do with running containers.
This post uses a Cloudflare DNS operator as the running example - an operator that watches CloudflareDNSRecord objects in the cluster and syncs them to the Cloudflare API. The source is here.
The problem operators solve
Helm charts and plain manifests handle static configuration well. You describe what you want, apply it, and Kubernetes makes it happen. But this works because Kubernetes itself knows how to reconcile pods, services, and config maps. It has no idea what a Cloudflare DNS record is.
The traditional answer is automation outside the cluster: a CI pipeline that calls curl against the Cloudflare API when a variable changes, a shell script someone runs manually, a Terraform workspace that drifts quietly for months. These work, but they all share the same problem: the external resource is not a first-class citizen in the cluster. You can’t kubectl get it, you can’t set a dependsOn, you can’t see its status alongside your other resources. And when someone edits it directly in the Cloudflare dashboard, nothing notices.
Operators bring external resources inside Kubernetes’ reconciliation boundary. Once you have an operator, a DNS record is just another Kubernetes object.
CRDs: giving Kubernetes new vocabulary
Before you can write an operator, you need to teach Kubernetes what your resource type looks like. Custom Resource Definitions (CRDs) are the mechanism. A CRD is itself a Kubernetes manifest - you apply it once, and from that point on the API server accepts and stores objects of that type.
The DNS operator’s CRD registers the CloudflareDNSRecord kind under dns.operator.io/v1. The CRD is a manifest like any other - you kubectl apply it once and the API server learns the new type:
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: cloudflarednsrecords.dns.operator.io # <plural>.<group>
spec:
group: dns.operator.io
scope: Namespaced
names:
plural: cloudflarednsrecords
singular: cloudflarednsrecord
kind: CloudflareDNSRecord
shortNames: [cfdr]
versions:
- name: v1
served: true
storage: true
# Status is a separate write path - the operator patches it without
# triggering an on.update on the spec.
subresources:
status: {}
# OpenAPI schema: the API server validates every object before storing it.
schema:
openAPIV3Schema:
type: object
properties:
spec:
type: object
required: [zone_id, name, type, content]
properties:
zone_id: { type: string }
name: { type: string }
type:
type: string
enum: [A, AAAA, CNAME, TXT, MX, NS, SRV, CAA]
content: { type: string }
ttl: { type: integer, default: 1 }
proxied: { type: boolean, default: false }
status:
type: object
x-kubernetes-preserve-unknown-fields: true
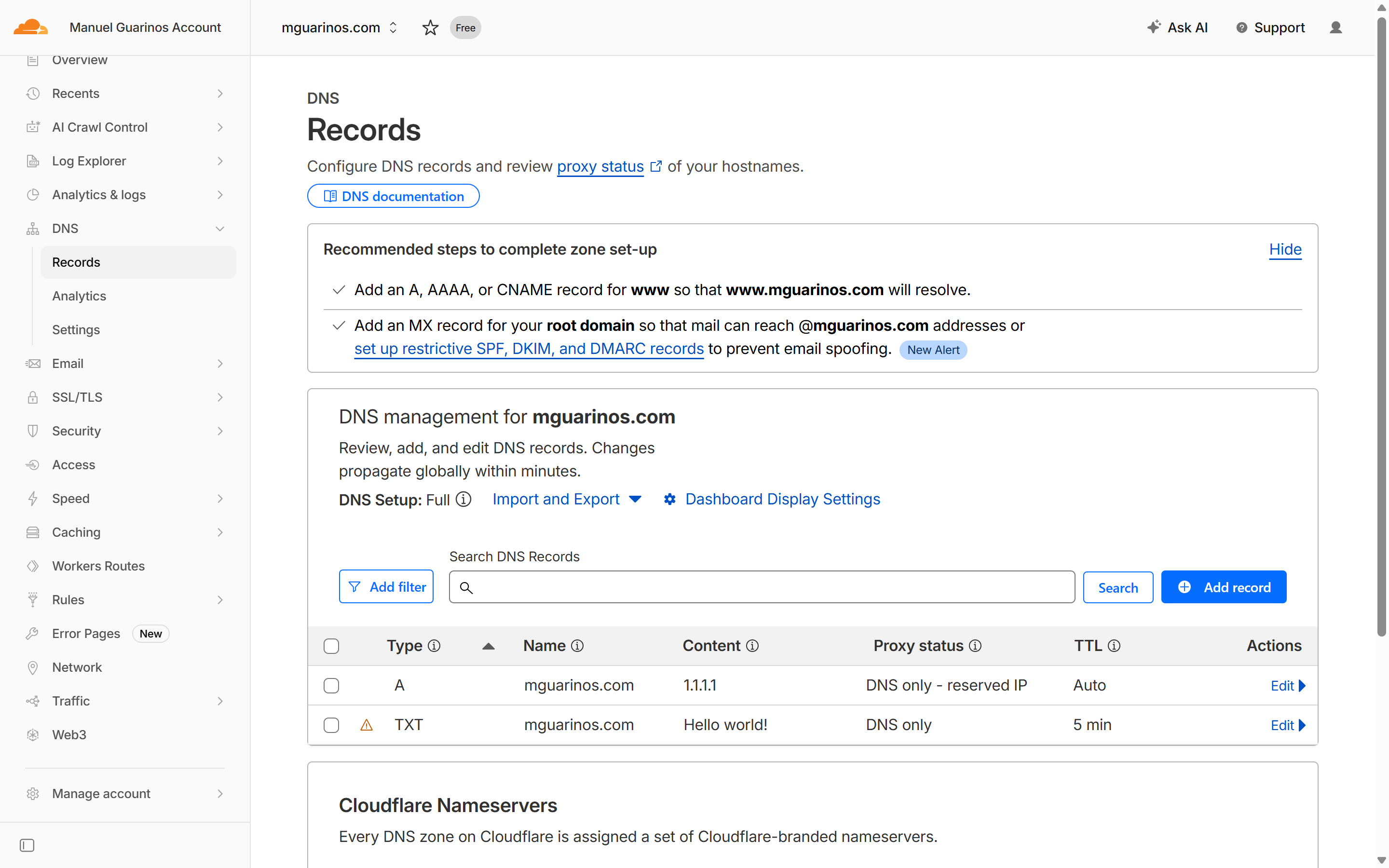
With the CRD applied and the operator running, you can create records by applying ordinary manifests. Here are two - an A record and a TXT record:
apiVersion: dns.operator.io/v1
kind: CloudflareDNSRecord
metadata:
name: mguarinos-com-apex-a
spec:
zone_id: "daeed8d03dd34a9923222a33e96986ff"
name: "mguarinos.com"
type: "A"
content: "1.1.1.1"
ttl: 1
---
apiVersion: dns.operator.io/v1
kind: CloudflareDNSRecord
metadata:
name: mguarinos-com-apex-txt
spec:
zone_id: "daeed8d03dd34a9923222a33e96986ff"
name: "mguarinos.com"
type: "TXT"
content: "Hello world!"
ttl: 300
kubectl apply -f records.yaml -n cf-operator
cloudflarednsrecord.dns.operator.io/mguarinos-com-apex-a created
cloudflarednsrecord.dns.operator.io/mguarinos-com-apex-txt
The operator picks up both objects immediately and creates the corresponding records in Cloudflare. A few seconds later:
kubectl get cfdr -n cf-operator
kubectl get cfdr -n cf-operator -o wide
NAME NAME TYPE CONTENT STATUS LAST SYNC AGE ZONE ID RECORD ID TTL PROXIED
mguarinos-com-apex-a mguarinos.com A 1.1.1.1 RecordSynced 2026-04-15T22:02:55Z 12s daeed8d03dd34a9923222a33e96986ff c62658232a4663be7d9610f69b186572 1 false
mguarinos-com-apex-txt mguarinos.com TXT Hello world! RecordSynced 2026-04-15T22:03:01Z 6s daeed8d03dd34a9923222a33e96986ff aafac48cbcc241ca882e1646e24098a8 300 false
CRDs also define a status subresource, which is a separate write path from the spec. The operator uses it to record what it observed: the Cloudflare record ID it created, the last sync timestamp, and a standard Kubernetes conditions array. The single condition (type: Synced) follows the True/False convention with a CamelCase reason token - RecordSynced, DriftDetected, or SyncFailed - and a human-readable message field. Using the standard conditions format means tools like kubectl wait, ArgoCD health checks, and other GitOps tooling understand the resource state without any custom logic. The subresource separation means the operator can patch status without triggering a reconciliation on the spec - there is no event loop between the two.
kubectl describe cfdr -n cf-operator mguarinos-com-apex-a
Name: mguarinos-com-apex-a
Namespace: cf-operator
Labels: <none>
Annotations: kopf.zalando.org/last-handled-configuration:
{"spec":{"content":"1.1.1.1","name":"mguarinos.com","proxied":false,"ttl":1,"type":"A","zone_id":"daeed8d03dd34a9923222a33e96986ff"}}
API Version: dns.operator.io/v1
Kind: CloudflareDNSRecord
Metadata:
Creation Timestamp: 2026-04-15T22:32:47Z
Finalizers:
dns.operator.io/cloudflare-cleanup
Generation: 1
Resource Version: 7945
UID: 1c4f445a-fa38-4584-aca7-f1c1d3580d4d
Spec:
Content: 1.1.1.1
Name: mguarinos.com
Proxied: false
Ttl: 1
Type: A
zone_id: daeed8d03dd34a9923222a33e96986ff
Status:
Conditions:
Last Transition Time: 2026-04-15T22:32:48Z
Message:
Reason: RecordSynced
Status: True
Type: Synced
last_sync: 2026-04-15T22:32:48Z
record_id: c6853b1fecfd4e3efbd263f835eb70fa
Events: <none>
The reconciliation loop
An operator is a process - typically a pod in the cluster - that watches the Kubernetes API for events on its custom resource type and reacts to them. The core of the DNS operator is four handlers:
on.create - when a CloudflareDNSRecord object appears, call cf.dns.records.create, then write the returned Cloudflare record ID into .status.record_id. That ID is the link between the Kubernetes object and the external resource. Without it, the operator cannot update or delete the record later.
on.update - when the spec changes, call cf.dns.records.update with the new values. If the status has no record_id (the operator was offline when the object was created), fall back to creating the record rather than failing.
on.delete - delete the Cloudflare record before allowing Kubernetes to remove the object. The finalizer (described below) is what makes this ordering possible.
timer - every 60 seconds, fetch the live record from Cloudflare and compare it to the spec. If they differ, revert Cloudflare to match Kubernetes.
When the operator pod starts you can see all of this initialising in the logs:
kubectl logs -n cf-operator cloudflare-dns-operator-6b55f8556d-5hw97
[2026-04-15 21:59:48,041] kopf._core.reactor.r [DEBUG ] Starting Kopf 1.44.5.
[2026-04-15 21:59:48,042] kopf.activities.star [DEBUG ] Activity 'on_startup' is invoked.
[2026-04-15 21:59:48,042] __kopf_script_0__src [INFO ] Cloudflare DNS Operator starting. namespace=cf-operator secret=cloudflare-api-token drift_interval=60s
[2026-04-15 21:59:48,043] helpers [DEBUG ] K8s config: loaded in-cluster service-account credentials.
[2026-04-15 21:59:48,052] kubernetes.client.re [DEBUG ] response body: {REDACTED}
[2026-04-15 21:59:48,054] __kopf_script_0__src [INFO ] Cloudflare token loaded successfully (length=53).
[2026-04-15 21:59:48,055] kopf.activities.star [INFO ] Activity 'on_startup' succeeded.
[2026-04-15 21:59:48,056] kopf._core.engines.a [INFO ] Initial authentication has been initiated.
[2026-04-15 21:59:48,056] kopf.activities.auth [DEBUG ] Activity 'login_via_client' is invoked.
[2026-04-15 21:59:48,057] kopf.activities.auth [DEBUG ] Client is configured in cluster with service account.
[2026-04-15 21:59:48,058] kopf.activities.auth [INFO ] Activity 'login_via_client' succeeded.
[2026-04-15 21:59:48,058] kopf._core.engines.a [INFO ] Initial authentication has finished.
[2026-04-15 21:59:48,152] kopf._cogs.clients.w [DEBUG ] Starting the watch-stream for customresourcedefinitions.v1.apiextensions.k8s.io cluster-wide.
[2026-04-15 21:59:48,153] kopf._cogs.clients.w [DEBUG ] Starting the watch-stream for cloudflarednsrecords.v1.dns.operator.io cluster-wide.
Together these four handlers mean the operator never needs to be told what changed. It observes events and acts on them. If the operator crashes and restarts, the reconciliation loop catches up automatically - any pending creates become updates, any missed deletes are replayed.

Finalizers: the guarantee on delete
Without a finalizer, kubectl delete removes the Kubernetes object immediately and the Cloudflare record is left behind. Finalizers prevent that.
When the operator starts, it registers the string dns.operator.io/cloudflare-cleanup as a finalizer on every object it manages. Kubernetes will not actually delete an object that has a finalizer on it - it only sets a deletionTimestamp and blocks. The API server then fires a delete event to the operator.
The operator’s delete handler calls cf.dns.records.delete. If that call succeeds, the handler returns and the operator removes the finalizer. Kubernetes sees the finalizer list is now empty and removes the object. If the Cloudflare call fails the handler raises a temporary error and the framework retries it every 30 seconds. The finalizer stays in place until the deletion is confirmed.
The result: as long as the operator is running, it is impossible for a kubectl delete to leave an orphaned DNS record.

Drift detection: Kubernetes as the source of truth
The timer handler is where the operator earns its keep.
Kubernetes stores the desired state. Cloudflare holds the live state. These can diverge whenever a human edits a record directly in the Cloudflare dashboard. Without an operator, that divergence is silent - your IaC says one thing, your DNS actually does another.
Every 60 seconds the operator fetches the record from Cloudflare and diffs content, proxied, and ttl against the spec. If anything differs, it logs the exact discrepancy and calls cf.dns.records.update to revert it. The condition reason is set to DriftDetected the moment divergence is found, and back to RecordSynced once the revert succeeds.
To see this in action: go to the Cloudflare dashboard and change the IP on mguarinos.com from 1.1.1.1 to 1.0.0.1. Within 60 seconds the operator logs:
[2026-04-15 22:03:55,213] kopf.objects [WARNING ] [cf-operator/mguarinos-com-apex-a] Drift detected on record id=c62658232a4663be7d9610f69b186572 name=mguarinos.com:
content : live='1.0.0.1' desired='1.1.1.1'
proxied : live=False desired=False
ttl : live=120.0 desired=1
Reverting to K8s spec.
This is what “Kubernetes is the source of truth” actually means in practice: not a policy, but a running process that enforces it. Any change made outside the cluster is overwritten within a minute.
Choosing a framework
Operators in Go using kubebuilder or the Operator SDK are the production standard. You get generated boilerplate, built-in status conditions, strong typing, and the full ecosystem of controller-runtime tooling. The tradeoff is that before writing a single line of business logic you are wiring up schemes, registering types, and configuring manager options.
Kopf (Kubernetes Operator Pythonic Framework) flips that tradeoff. A handler is a decorated Python function. The framework handles watches, retries, status patching, finalizer registration, and leader-election. For an operator with a small surface area - a handful of handlers, one external API - the reduction in boilerplate is significant without giving up the important guarantees.
The DNS operator uses kopf. The operator logic is split across three focused files: constants and configuration, shared helpers (K8s client, Cloudflare client, status utilities), and the kopf handlers themselves. For a team already fluent in Python and operating against well-understood Python SDKs (e.g. the Cloudflare client), this is often the right call.
When to write an operator
An operator is the right tool when:
- You have an external resource with a lifecycle (create, update, delete) that needs to track Kubernetes objects.
- You want drift detection.
- The resource type is long-lived and managed by multiple people, where a CI script or manual Terraform run is too fragile.
An operator is overkill when you just need to run a job on deploy, transform a config value, or provision something once. A Job, a Helm hook, or an init container is simpler and easier to reason about.